PostgreSQL® 9.5: Block Range Index (BRIN)
| Kategorien: | PostgreSQL® |
|---|---|
| Tags: | PostgreSQL® |
BRIN ist ein in PostgreSQL® 9.5 neu eingeführter Indextyp, der Name steht für Block Range INdex.
Was ist ein Block Range Index?
Die meisten Indexe werden als Baumstruktur realisiert mit deren Hilfe gesuchte Einträge sehr schnell gefunden werden können. Der Aufwand für Suchanfragen in derartig organisierten Indexstrukturen beträgt in der Regel O(log(Anzahl der Einträge)). Ein solcher Baum skaliert mit wachsender Datenmengen, bezogen auf die Abfragezeit folglich logarithmisch. Es spielt für das Auffinden eines bestimmten Eintrags keine große Rolle, ob eine Tabelle 100.000 oder 100.000.000 Zeilen enthält ( log(100.000) ≈ 11,5 | log(100.000.000) ≈ 18,4). Der Speicherbedarf des Baumes wächst jedoch linear mit den Daten, was dazu führt, dass Indexe sehr groß und entsprechend „unhandlich“ werden. Sollen bei einer Tabelle mehr als eine Spalte indiziert werden kann das schnell dazu führen, dass die Indexe ein vielfaches des Speicherplatz der Daten selbst benötigen. Doch auch der Verzicht auf weitere Indexe ist bei großen Datenmengen nicht praktikabel, da beim sequentiellem Zugriff im Zweifel sämtliche Daten gelesen werden müssen.
BRIN Indexe schaffen an dieser Stelle sehr attraktive Einsatzmöglichkeiten. Wie der Name vermuten lässt, werden nicht sämtliche Einträge einzeln im Index aufgeführt, sondern ganze Blöcke. Da ein Block nicht durch einen einzelnen Wert dargestellt werden kann, wird für jeden Block ein Minimal- und Maximalwert abgelegt. Verwendet nun eine Abfrage eine indizierte Spalte muss nicht der gesamte Datenbestand durchsucht werden, sondern nur die Blöcke in denen der gesuchte Wert überhaupt enthalten sein kann.
Einschränkungen
Hier offenbart sich allerdings auch gleichzeitig ein Nachteil dieses Indextyps. Sind die Daten völlig zufällig verteilt, kann es nötig sein, sehr viele Blöcke zu durchsuchen und der Geschwindigkeitsvorteil fällt nur gering aus. Sind die Daten jedoch natürlich sortiert, z.B. Rechnungsnummer oder Bestelldatum in einer Bestelltabelle, oder bilden natürliche Gruppen mit gleichen bzw. ähnlichen Werten, kann das volle Potenzial genutzt werden. Abfragen mit einfachen Vergleichsoperationen werden je nach Datenstruktur und Blockgröße eher weniger von den Vorteilen eines BRIN-Index profitieren. Bereichsabfragen auf günstig verteilten oder gar sortierten Datenbeständen werden im Vergleich zu herkömmlichen sequentiellen Abfragestrategien massiv beschleunigt.
Klein, kleiner, BRIN
Der Hauptvorteil ist jedoch der Speicherverbrauch, so ist ein BRIN z.T. um den Faktor 10.000 kleiner als ein entsprechender Btree. Nachfolgend ein Beispiel von zwei Indexen auf der gleichen Spalte vom Typ timestamp einer 7300 MB großen Tabelle. Zuerst ein Btree- und anschließend der BRIN-Index, der Größenunterschied beträgt etwa Faktor 7000:
# \di+
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------------+-------+----------+-----------+---------+-------------
public | brin_test_time_btree | index | postgres | brin_test | 2142 MB |
public | brin_test_time_brin | index | postgres | brin_test | 288 kB |
Blockgröße
Die Blockgröße kann an die zugrunde liegenden Daten angepasst werden. Bei natürlich sortierten Spalten ist die genaue Blockgröße nicht ganz unkritisch. Hier sind größere Blöcke und damit ein noch kleinerer Index je nach Abfragen von Vorteil. Gibt es im Datenbestand jedoch häufig Ausreißer oder sind die Einträge nicht natürlich sortiert, kann die Wahl einer kleineren Blockgröße die Performance stark verbessern. Beim Anlegen des Index kann die Anzahl an indizierten Tabellenblöcken pro BRIN-Block angegeben werden. Der Vorgabewert ist 128, bei der Standardpagegröße von 8 kB ergibt sich eine indizierte Tabellenblockgröße von 1 MB. Nachfolgend Beispiele für Indexe zwischen 8 Pages (64 kB) und 2048 Pages (16 MB) großen Blöcken:
# \di+
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+--------------------------+-------+----------+-----------+---------+-------------
public | brin_test_time_btree | index | postgres | brin_test | 2142 MB |
public | brin_test_time_brin_8 | index | postgres | brin_test | 3936 kB |
public | brin_test_time_brin_32 | index | postgres | brin_test | 1016 kB |
public | brin_test_time_brin_128 | index | postgres | brin_test | 288 kB | Standard
public | brin_test_time_brin_256 | index | postgres | brin_test | 160 kB |
public | brin_test_time_brin_512 | index | postgres | brin_test | 104 kB |
public | brin_test_time_brin_1024 | index | postgres | brin_test | 72 kB |
public | brin_test_time_brin_2048 | index | postgres | brin_test | 56 kB |
Abfrageperformance
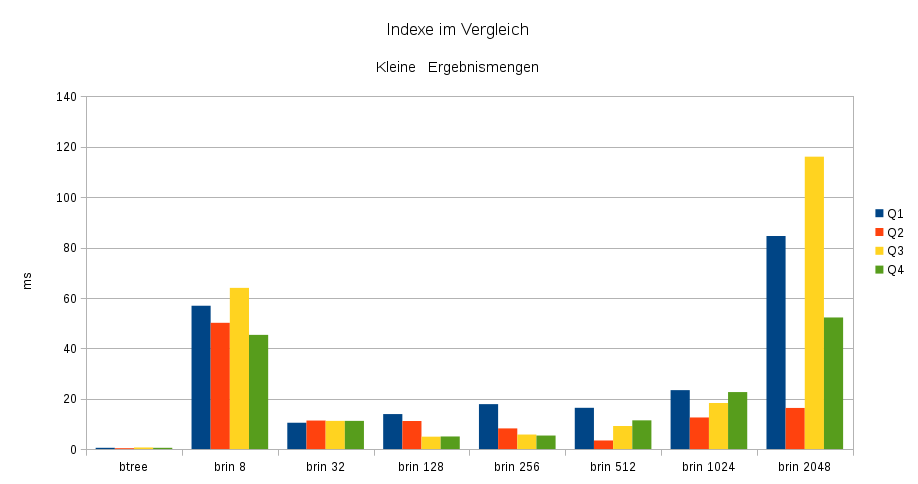
Die nachfolgenden Diagramme zeigen die Ausführungszeiten von fünf SQL-Abfragen und deren Nutzung der verschiedenen Indexe. Die Abfragen Q1 bis Q4 liefern nur kleine Ergebnismengen zurück. Hier zeigt sich die Effektivität des Btree-Indexes sowie der Overhead durch die kleine Blockgröße beim 8-Page-BRIN. Mit steigender Blockgröße sinkt dieser Overhead, doch die Menge an zu durchsuchenden und durch nur ein Min/Max-Paar repräsentierten Daten steigt. Dieser negative Effekt lässt sich an den Indexen mit Blockgröße ab 1024 Pages erkennen. Die von PostgreSQL® verwendete Standardgröße von 128 Pages pro Block ist bei den hier verwendeten Testdaten ein sehr guter Wert, auch wenn z.B. Q2 von einer etwas höheren Blockgröße profitieren würde. Je nach Abfrage und Daten, kann die sinnvollste Blockgröße natürlich variieren.
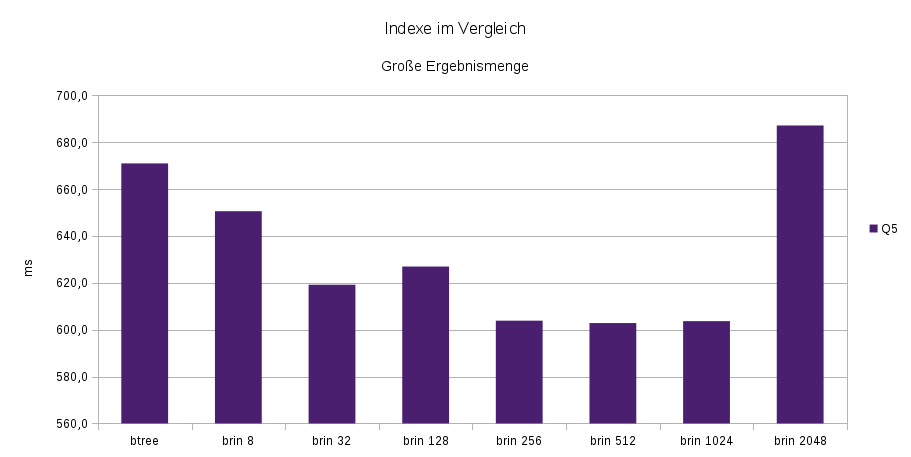
Abfrage Q5 liefert wesentlich mehr Ergebnisse zurück, wodurch das Auffinden der einzelnen Ergebnisse weit weniger die Gesamtzeit beeinflusst. Die Wahl des Indexes spielt hier eine untergeordnete Rolle. Durch die einfachere Möglichkeit ganze Blöcke zurückzuliefern haben Block Range Indexe hier einen Vorteil.
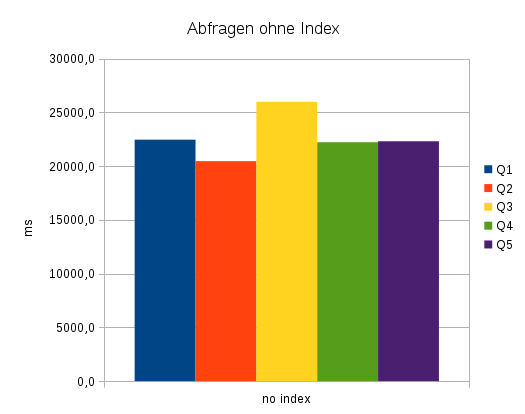
Um keine logarithmische Skala verwenden zu müssen, sind die Ausführungen ohne Indexnutzung in einem zusätzlichen Diagramm dargestellt. Die Ausführungszeiten liegen hier alle im Bereich von 20 s bis 26 s.
Wartung
Block Range Indexe werden nicht automatisch aktualisiert und die Minimal- und Maximalangaben pro Spalte sind nicht zwingend genau, sondern verstehen sich als obere und untere Schranken. Wird eine Tabelle ständig erweitert (INSERT) verschlechtert dies die Qualität des Index nicht. Werden jedoch die vorhandenen Daten Umstrukturiert oder geändert (UPDATE, DELETE), kann es nötig werden einen BRIN-Index neu zu erzeugen. Ob PostgreSQL® hier um einen automatischen Mechanismus erweitert wird, ist noch nicht abschließend geklärt.
Fazit / tl;dnr
Die Verwendung von BRIN ist nicht überall sinnvoll, bei der Analyse sehr großer Datenbestände, die in irgendeiner Form gruppiert oder sortiert sind, spielen Block Range Indexe jedoch ihre Vorteile aus. Durch die stetig wachsende Datenmengen ergeben sich hier viele spannende Anwendungsfälle. Beim gezielten Einsatz von Block Range Indexen unterstützt unser PostgreSQL® Competence Center Sie natürlich genauso gerne wie bei allen anderen Themen und Problemstellungen rund um PostgreSQL®.
Anhang
Wenn Sie bereits eine Vorabversion von PostgreSQL® 9.5 testen und 10 GB freien Speicherplatz haben, können Sie die oben gezeigten Beispiele leicht selbst nachstellen. Für eigene Experimente sind Tabellen- und Indexdefinitionen sowie die verwendeten Abfragen angehängt.
-- Tabelle
CREATE TABLE brin_test AS
SELECT
series AS id,
md5(series::TEXT) AS value,
'2015-10-31 13:37:00.313370+01'::TIMESTAMP + (series::TEXT || ' Minute')::INTERVAL AS time
FROM
generate_series(0,100000000) AS series;
-- Indexe
CREATE INDEX brin_test_time_btree ON brin_test USING btree (time);
CREATE INDEX brin_test_time_brin_8 ON brin_test USING brin (time) WITH (pages_per_range=8);
CREATE INDEX brin_test_time_brin_32 ON brin_test USING brin (time) WITH (pages_per_range=32);
CREATE INDEX brin_test_time_brin_128 ON brin_test USING brin (time) WITH (pages_per_range=128);
CREATE INDEX brin_test_time_brin_256 ON brin_test USING brin (time) WITH (pages_per_range=256);
CREATE INDEX brin_test_time_brin_512 ON brin_test USING brin (time) WITH (pages_per_range=512);
CREATE INDEX brin_test_time_brin_1024 ON brin_test USING brin (time) WITH (pages_per_range=1024);
CREATE INDEX brin_test_time_brin_2048 ON brin_test USING brin (time) WITH (pages_per_range=2048);
-- Abfragen
SELECT * FROM brin_test WHERE time = '2100-11-11 13:37:00.31337'; -- Q1
SELECT * FROM brin_test WHERE time = '2205-12-19 00:16:00.31337'; -- Q2
SELECT * FROM brin_test WHERE time >= '2016-11-11' AND time <= '2016-11-12'; -- Q3
SELECT * FROM brin_test WHERE time >= '2100-11-11' AND time <= '2100-11-12'; -- Q4
SELECT * FROM brin_test WHERE time >= '2200-01-01 00:00:00.00000'; -- Q5
-- Ergebnisse
-- btree brin1 brin 8 brin 32 brin 128 brin 256 brin 512 brin 1024 brin 2048 no index
-- Q1 0,5 348,6 56,9 10,5 13,9 17,8 16,4 23,4 84,6 22450,3
-- Q2 0,4 318,4 50,1 11,3 11,1 8,2 3,4 12,6 16,3 20455,7
-- Q3 0,6 327,2 64,0 11,2 4,9 5,8 9,1 18,3 116,1 25972,1
-- Q4 0,5 316,9 45,3 11,2 5,0 5,4 11,4 22,6 52,2 22216,3
-- Q5 670,9 902,2 650,5 619,2 626,9 603,8 602,8 603,6 687,1 22305,2
Weiterführende Informationen: BRIN Indexes
| Kategorien: | PostgreSQL® |
|---|---|
| Tags: | PostgreSQL® |

über den Autor
Alexander Sosna
Projektleiter
zur Person
Alexander Sosna arbeitet seit 2014 im credativ Datenbank-Team und hat dort die organisatorische Leitung. Außerdem nimmt er die Aufgabe des teamübergreifenden Projektleiters wahr. Während des Wintersemesters erfüllt er zusätzlich einen Lehrauftrag für IT-Security an der Hochschule Niederrhein.