Erweiterung des Instaclustr Monitoringsystems: Verwendung von Redis™ als Cassandra®-Cache
| Kategorien: | HowTos Instaclustr® News |
|---|---|
| Tags: | Cassandra Kafka Redis |
Monitoring im großen Maßstab
In dieser Blogserie berichten wir, wie wir unser Metriksystem – hauptsächlich unseren Apache Cassandra®-Cluster mit dem Namen Instametrics – bis an die Grenzen gebracht haben und wie wir anschließend die tägliche Last verringern konnten.
Der Problemraum
Instaclustr hostet Hunderte von Clustern und betreibt Tausende von Knoten, von denen jeder alle 20 Sekunden Metriken übermittelt. Von betriebssystembezogenen Metriken wie CPU-, Laufwerks- und Speichernutzung bis zu anwendungsspezifischen Metriken wie Cassandra-Leselatenz oder Kafka®-Consumer-Lag:
Instaclustr stellt seinen Kunden diese Metriken auf unserer Metrik-API zur Abfrage bereit. Mit zunehmendem Wachstum und dem Hinzukommen weiterer Kunden und Produkte muss die zugrundeliegende Infrastruktur skaliert werden, um die wachsende Zahl von Knoten und Metriken zu unterstützen.
Unsere Monitoring-Pipeline
Wir erfassen Metriken von jedem Knoten über unsere Monitoring-Anwendung, die auf dem Knoten ausgeführt wird. Diese Anwendung ist für die periodische Erfassung verschiedener Metriken und deren Umwandlung in ein übermittelbares Standardformat verantwortlich.
Anschließend übermitteln wir die Metriken an unsere zentrale Monitoring-Infrastruktur, wo sie von unseren Monitoring-Servern verarbeitet werden. Das umfasst Operationen wie z. B.:
- Berechnung neuer Metriken, sofern erforderlich; anschließend Ausführung von Zählern für verschiedene Metriken, Mapping verschiedener Cloudservice-Dateisystempfade in gemeinsame Pfade und Ähnliches.
- Verarbeitung der Metriken, Anwendung von Regeln und Erzeugung von Berichten oder Alarmen für unser technisches Betriebsteam.
- Speichern der Metriken; der primäre Datenspeicherort ist unser Apache Cassandra-Cluster mit dem Namen Instametrics – dieser wiederum läuft als verwalteter Cluster auf unserer Plattform, unterstützt von unserem technischen Betriebspersonal, wie bei allen unseren Clustern.
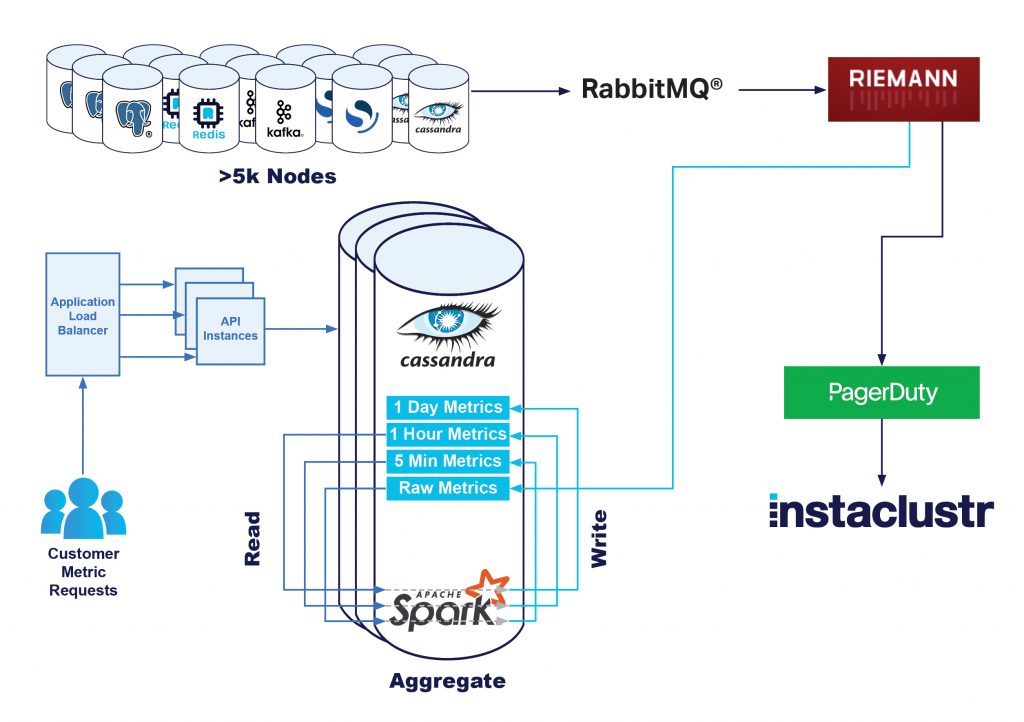
In einem früheren Blog hat unser Plattform-Team berichtet, wie wir die Erfassungs-Pipeline für unsere Metriken verbessert haben, um unseren Cassandra-Cluster Instametrics stark zu entlasten. Dies wurde durch eine Kafka-Streaming-Pipeline erreicht.
Entlastung der API
Mit zunehmender Vergrößerung unseres Produktangebots und mehr Kunden und Knoten fragten wir uns, wo bei unserer Monitoring-Pipeline Verbesserungsbedarf bestehen könnte.
Unser Fokus lag dabei unter anderem auf unserer Monitoring REST API, die angesichts von immer mehr Kunden, die unsere Metriken so schnell wie möglich abrufen wollen, zunehmend Latenz aufwies. Alle 20 Sekunden werden Metriken veröffentlicht, und einige Kunden schnappen sich diese, sobald sie zur Verfügung stehen.
Um die Latenzen und an die Kunden berichtete Fehler zu verringern, suchten wir nach der Ursache für die Probleme. Nachdem wir die Kapazität der API-Server selbst verstärkt hatten, kamen wir nach einiger Analyse zu dem Schluss, dass Cassandra eine relativ aufwändige Methode (in Bezug auf Kosten und CPU-Last) ist, um die hohe Arbeitslast für frische Metriken zu bedienen. Um weiterhin alle Anforderungen an unseren Instametrics-Cluster mit der gewünschten Latenz bedienen zu können, müsste dieser weiter skaliert werden, um die Last angemessen bewältigen zu können. Wir mussten Anfragen, die von mehreren Dimensionen kamen, erhebliche Schreiblast aufgrund des Speicherns der Metriken, eine große Last aufgrund der ursprünglichen Spark-basierten Roll-up-Berechnungen der Metriken und nicht zuletzt die Leselast aufgrund der API-Anfragen bewältigen.
Unser Plattform-Team hatte bereits damit begonnen, die Berechnungen beim Erfassen der Metriken zu reduzieren, aber wir wollten zusätzlich auch die Leselast auf unserem Cassandra-Cluster senken. Idealerweise wollten wir etwas modulares haben, das wir kontinuierlich durch Hinzufügen weiterer Cluster und Produkte skalieren könnten, um unseren Cassandra-Cluster zu entlasten und die Benutzererfahrung zu verbessern.
Redis kommt ins Spiel
Für das Problem der Leselast war Redis eine offensichtliche Wahl. Unser Instaclustr for Redis-Angebot wurde entwickelt, um Unternehmen bei der Lösung genau dieser Art von Problemen zu helfen. Wir erstellten einen Plan für die Nutzung unseres Terraform Provider und erstellten einen Redis-Cluster, konfiguriert und vernetzt mit unseren Kernanwendungen, der vollständig zur Bedienung unserer Metrikanfragen bereitstand.
Die Herausforderung war nun, die Metriken dorthin zu bekommen.
Das richtige Datenmodell
Wir hatten immer damit gerechnet, dass die in Redis gespeicherten Daten etwas anders als diejenigen in Instametrics sein würden.
Unser Cassandra-Cluster speichert alle Rohmetriken 2 Wochen lang. Eine solche Datenmenge in Redis zu speichern, wäre aus Kostengründen nicht machbar. Der Grund dafür ist, dass Redis diese Informationen statt auf einem Laufwerk (wie bei Cassandra) im Arbeitsspeicher ablegt. Das ermöglicht zwar erheblich schnellere Zugriffe, ist aber auch deutlich teurer.
Zwar können Kunden Metriken abfragen, die vor 2 Stunden oder 2 Tagen erfasst wurden, aber wir wissen, dass der Großteil der API-Last von Kunden verursacht wird, die konstant die neuesten verfügbaren Metriken abfragen, um sie oftmals in ihre eigenen Monitoring-Pipelines zu übertragen. Tatsächlich brauchen wir nur etwa die letzte Minute an Daten in Redis, um den Großteil an API-Anfragen zu bedienen.
Wir wissen außerdem, dass nicht jeder Kunde die Monitoring-API verwendet – viele unserer Kunden sehen sich die Metriken einfach in unserer Konsole an. Und diejenigen, die sie selbst speichern möchten, verwenden sie möglicherweise nicht rund um die Uhr, sondern speichern sie nur in bestimmten Situationen. Indem wir nur Metriken von denjenigen Clustern zwischenspeichern, bei denen über die API ausgelesen wird, können wir unsere Datenübertragungskosten und die CPU- und Speicherauslastung verringern.
Wenn man dann noch bedenkt, dass sich die meisten unserer API-Anfragen auf die neuesten Metriken beziehen, wenden wir eine TTL (Time To Live) von 15 Minuten auf alle Redis-Datensätze an und speichern nur für diejenigen Kunden Metriken zwischen, die in der letzten Stunde die Monitoring-API verwendet haben.
Der erste Versuch
Die einfachste Lösung, die minimale Änderungen an unserem vorhandenen Stack erforderte, war die Einführung dualer Schreibvorgänge in der Monitoring-Pipeline. Zusätzlich zum Schreiben von Rohmetriken in unseren Cassandra-Cluster schreiben wir sie nun auch in unseren Redis-Cluster.
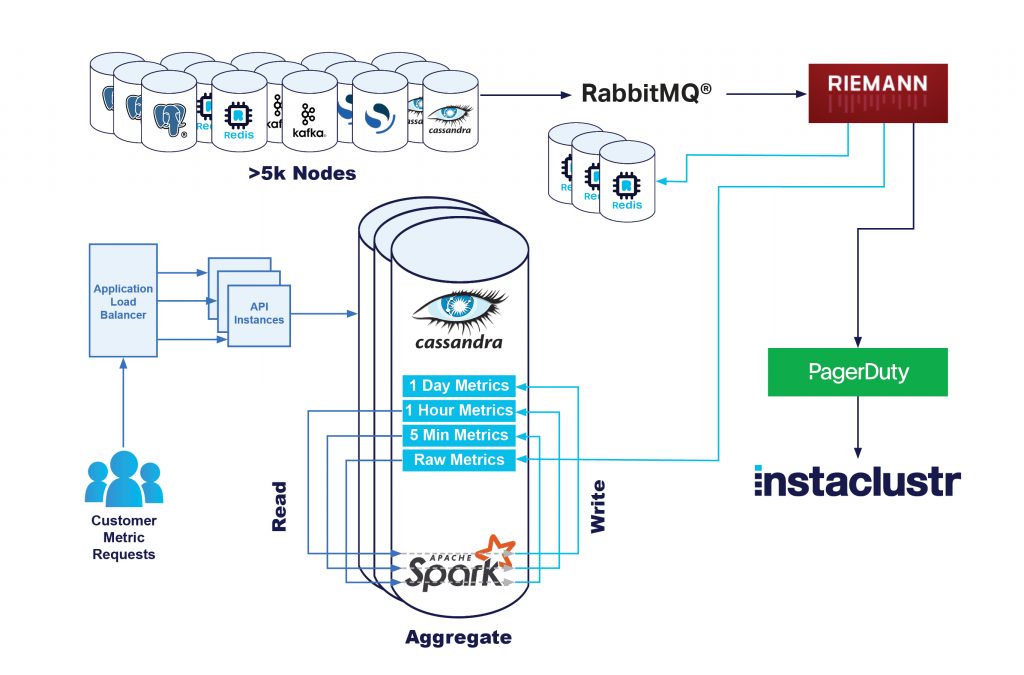
Das war nicht ganz gefahrlos, da die Monitoring-Server unter konstant hoher Last stehen. Wenn die Pipeline nicht schnell genug bereinigt wurde, entstand eine Art negativer Feedback-Schleife, die schnell zu einem Ausfall führte.
Diese Pipeline ist jedoch ziemlich gut instrumentiert, und wir können einen Anfragenstau erkennen, bevor er zu einem großen Problem wird.
Deshalb schrieben wir ein Übermittlungsprogramm für Redis-Metriken und verknüpften sie mit unserer Verarbeitungs-Engine hinter einem Feature Flag. Dies wandten wir dann auf eine kleine Gruppe der Monitoring-Server an und beobachteten, was passierte.
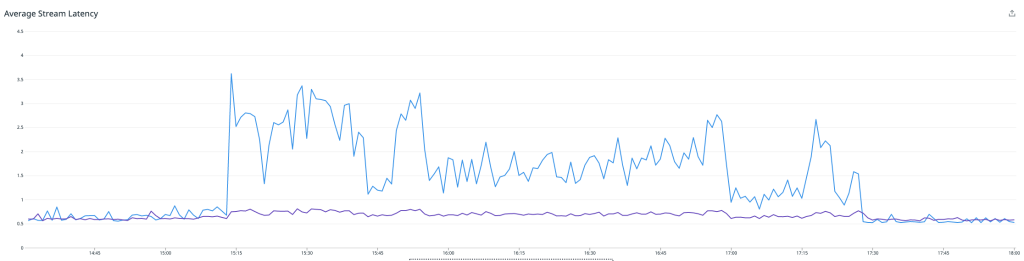
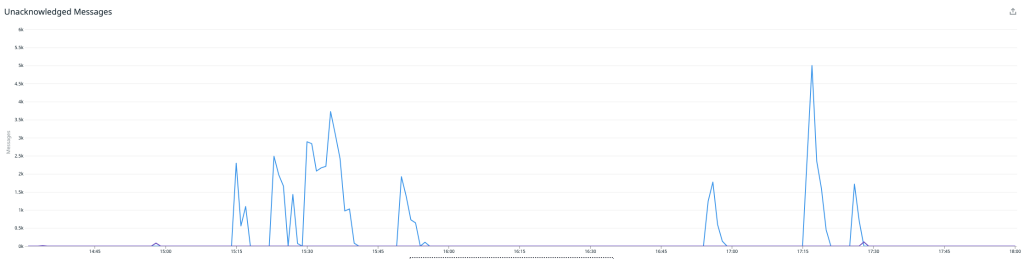
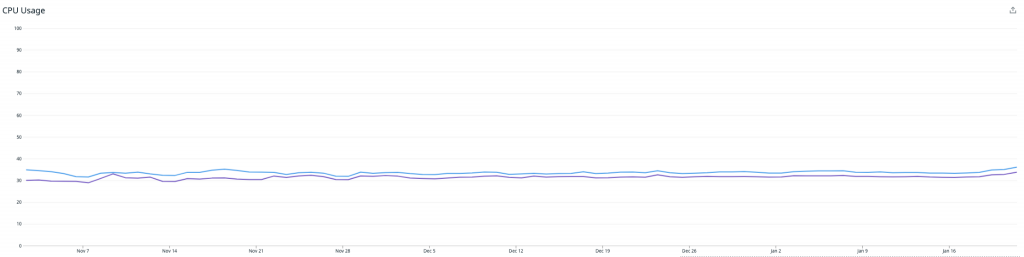
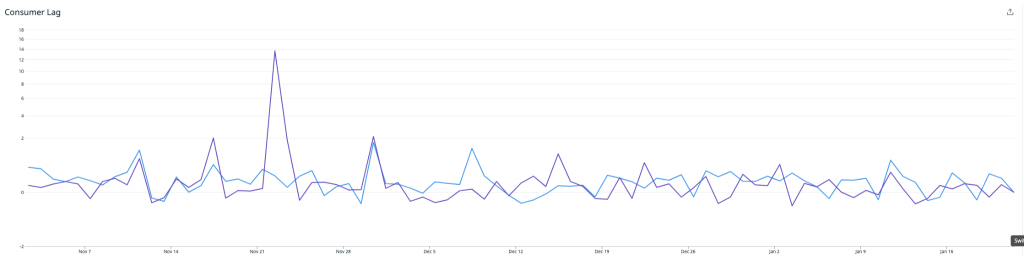
Der Durchschnitt der Monitoring-Boxen mit aktivierter Funktion ist blau dargestellt, und die anderen sind lila. Wie das Bild oben zeigt, schossen unsere Latenzen in die Höhe, was zu entsprechenden Warteschlangen führte. Wir beschlossen, das Experiment abzubrechen und unsere Erkenntnisse auszuwerten.
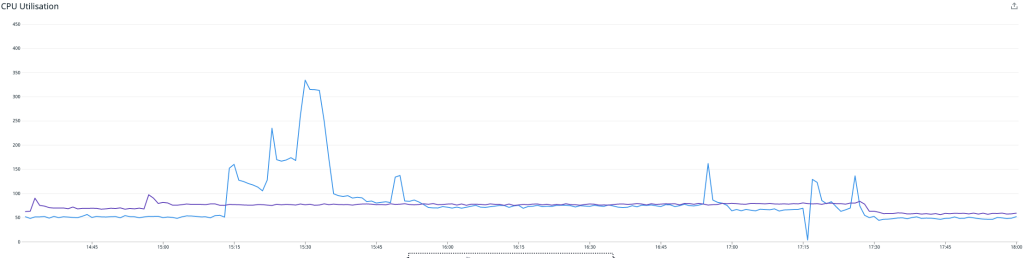
Außerdem wandten wir uns an das Instaclustr Technical Operations-Team, das sich den Redis-Cluster kurz für uns ansah und zu dem Schluss kam, dass dieser weitgehend problemlos lief. Der Engpass befand sich nicht im Redis-Cluster selbst.
Diese Grafik zeigt die CPU-Auslastung – die periodischen Spitzen sind auf AOF-Rewriting zurückzuführen, das wir in einem späteren Artikel behandeln werden. Ohne diese erreichten wir eine CPU-Last von ca. 10 %, während etwa 30 % der Gesamtmetriken aufgenommen wurden.
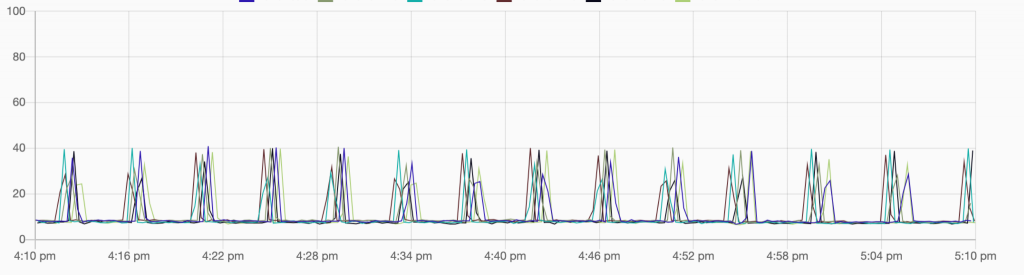
Insgesamt ein ganz ordentlicher erster Versuch, aber wir mussten noch nachbessern!
Versuch 2:
Wir stellten eine deutlich höhere CPU-Auslastung auf unseren Monitoring-Servern fest, als wir erwartet hatten, und suchten nach Verbesserungen. Nachdem wir ein wenig herumgesucht hatten, fanden wir eine Funktion, die moderate Kosten verursachte, wenn sie nur einmal pro Metrikerfassung aufgerufen wurde, die jedoch aufgrund des neuen Redis-Ziels noch deutlich effektiver war, wenn wir sie 2- bis 3-mal aufriefen.
Wir machten uns an die Arbeit, den Aufruf so zu konsolidieren, dass er nur einmal je Zyklus stattfand, und schalteten alles wieder ein.
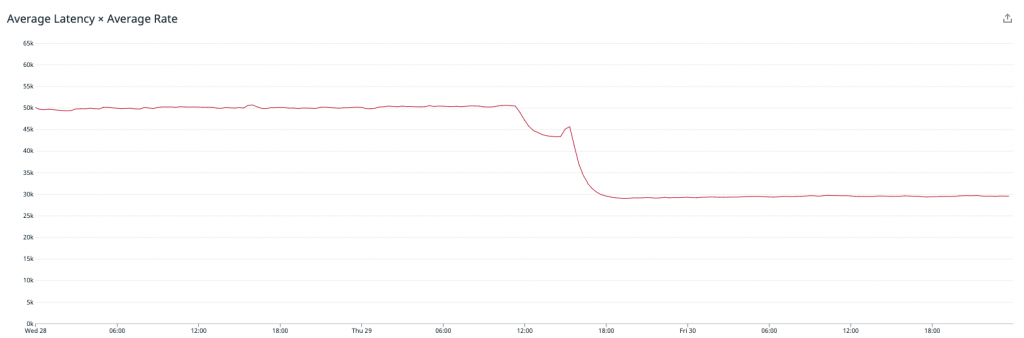
Wie man sehen kann, ging die Durchschnittslatenz unserer Verarbeitungs-Engine erheblich zurück – auch wenn wir das Metrik-Übermittlungsprogramm für Redis einschalteten! Unser Redis-Cluster lief erneut problemlos. Jeder Knoten verarbeitete 90.000 Arbeitsschritte pro Sekunde bei rund 70 % CPU-Auslastung mit reichlich freiem Speicher.
Ziel erreicht! Nun war es an der Zeit, diese Metriken in der API zu verwenden.
Versuch 2: Fortsetzung
Leider ohne Erfolg.
Nachdem wir das Problem mit der Verarbeitungslatenz gelöst hatten, glaubten wir uns auf der richtigen Spur. Doch nachdem wir die Server einige Tage lang sich selbst überlassen hatten, beobachteten wir sporadische CPU-Spitzen, bei denen die Server außer Kontrolle gerieten, abstürzten und neu starteten.
Außerdem bemerkten wir einen entsprechenden Anstieg bei der Latenz im Anwendungs-Streaming – was darauf hindeutete, dass diese allmählich langsamer wurden, schließlich abstürzten und dann neu starteten.
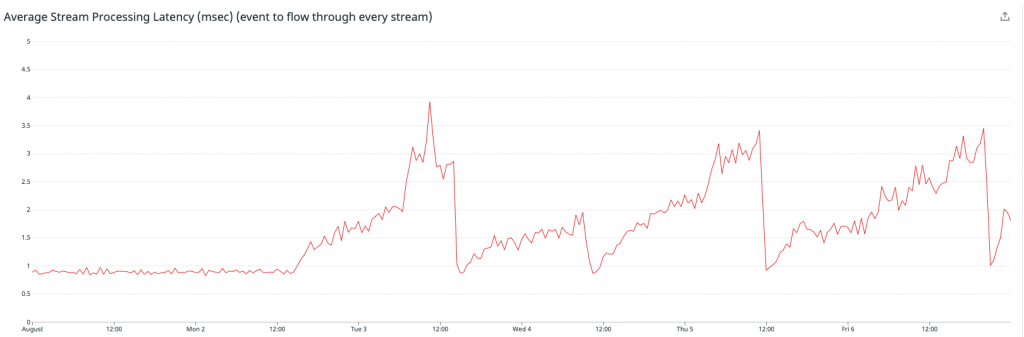
Dies wurde zunächst bei den am stärksten belasteten Servern beobachtet, aber mit der Zeit zeigten alle von ihnen ähnliche Symptome.
Wir mussten die Übermittlung von Metriken an Redis erneut abschalten und alles noch einmal durchdenken.
Das Problem war, dass uns so langsam die Optimierungsmöglichkeiten ausgingen. Unsere Monitoring-Pipeline ist in Clojure geschrieben, und die Optionen für Kundenbibliotheken und Support sind begrenzt. Oft müssen wir auf native Java-Bibliotheken zurückgreifen, um die volle Funktionalität zu erhalten, die wir brauchen, aber das kann neue Probleme mit sich bringen.
An diesem Punkt steckten wir irgendwie fest.
Die Rettung: Kafka
Glücklicherweise waren wir nicht das einzige Team, das an einer Verbesserung der Monitoring-Pipeline arbeitete. Eines unserer anderen Teams näherte sich einer endgültigen Implementierung ihres Kafka-Metrics-Übermittlungsprogramms an.
Hier sollten die Rohmetriken zunächst an einen Kafka-Cluster und anschließend an ihr endgültiges Ziel, den Instametrics Cassandra-Cluster, gehen.
Sobald sich die Metriken in Kafka befinden, eröffnen sich uns ganz neue Möglichkeiten. Wir können es uns leisten, die Metriken etwas langsamer aufzunehmen, da wir damit am Eingang keine kritische Warteschlange mehr blockieren, wir können Consumer leichter skalieren und im Fall einer Störung beliebig im zeitlichen Verlauf der Einträge springen.
Während die anderen an einer endgültigen Stabilisierung arbeiteten, schrieben wir die zweite Version unseres Metrics-Übermittlungsservice für Redis. Dieses Mal holten wir die Metriken aus Kafka und konnten eine kleine Java-Anwendung erstellen, die auf einem vertrauten Satz von Tools und Standards basiert.
Das bestätigte unsere Wahl von Kafka als Grundlage für unsere Metrik-Pipeline. Wir sehen bereits jetzt, welche Vorteile es hat, wenn mehrere Teams mehrere Anwendungen erstellen und alle auf den gleichen Nachrichtenstrom zugreifen können.
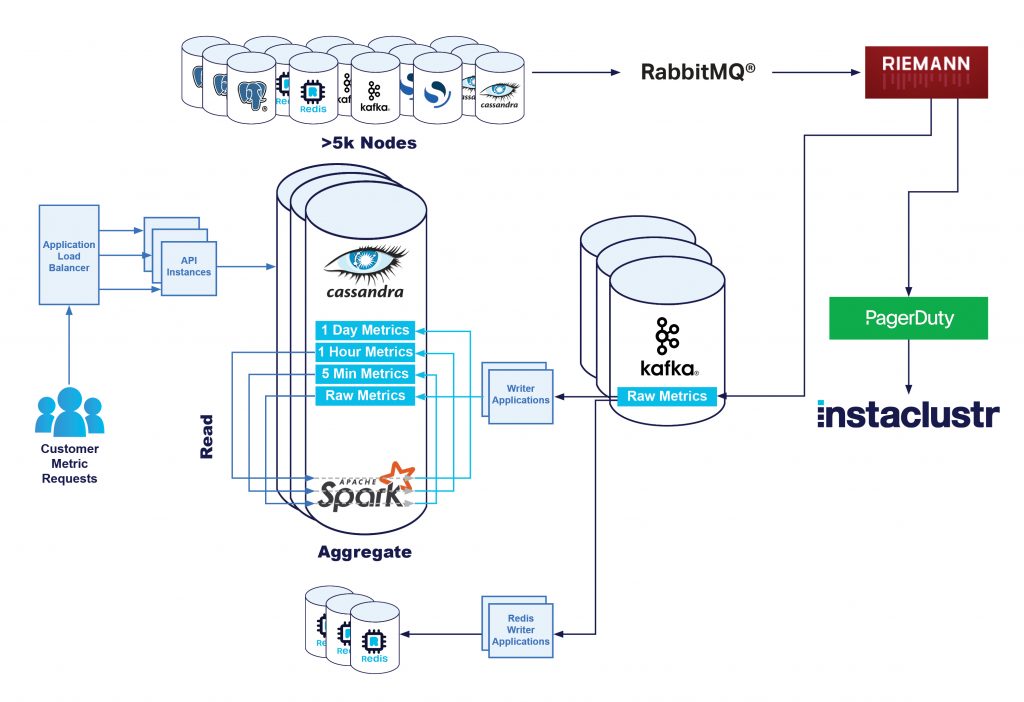
Indem wir die oben genannten Einschränkungen rund um die Verarbeitungszeit auf unseren Monitoring-Instanzen beseitigten, konnten wir diesen Mikroservice in kürzester Zeit und mit minimalem Aufwand bereitstellen, und wir haben alle Instrumente, die zur Verwendung von jmx-Metriken und Protokoll-Tools nötig sind.
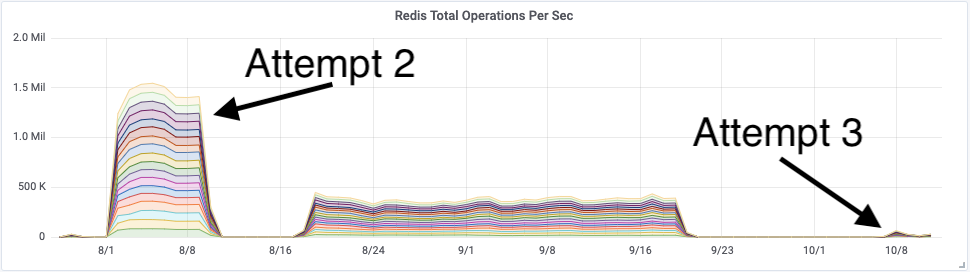
Versuch Nr. 3 Redis Writer als dedizierte Kafka Consumer-Anwendungen
Die Entwicklung einer Anwendung zum Lesen von Kafka und Schreiben auf Redis war relativ einfach, und es dauerte nicht lange, bis wir etwas in der Hand hatten, um mit dem Testen zu beginnen.
Wir setzten unsere neue Redis Writer-Anwendung in unserer Testumgebung ein und ließen das Ganze zwei Wochen lang laufen, um es auf Stabilität und Korrektheit zu prüfen. Unsere Testumgebung hat im Vergleich zur Produktionsumgebung nur eine sehr geringe Monitoring-Last. Nachdem jedoch sowohl die Redis Writer als auch der Redis-Cluster nach zwei Wochen noch immer stabil waren, entschieden wir uns, die Writer an der Produktions-Workload zu testen.
Hier zeigte sich ein weiterer Vorteil der Nutzung von Kafka als Monitoring-Infrastruktur. Das Risiko dabei war extrem gering, denn selbst wenn der Redis Writer überfordert wäre, angehalten werden müsste oder einfach fehlerhaft wäre, hätte dies für unseren Kafka-Cluster nur eine geringe Zusatzlast bedeutet – ohne dass der Rest des Systems davon betroffen gewesen wäre.
Nachdem wir die Redis Writer-Anwendungen in die Produktion gebracht hatten, wurde schnell klar, dass die Writer mit dem Datenverkehr nicht mithalten würden. Die CPU-Auslastung war am Anschlag, und der Consumer-Lag für die Redis Writer Consumer-Gruppe stieg schnell an. Der Gesamtdurchsatz war nur ein Bruchteil dessen, was die ursprüngliche Riemann-basierte Lösung erreichen konnte.
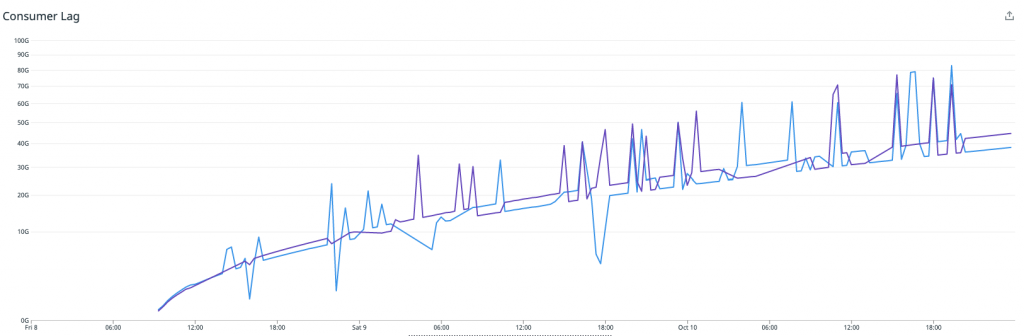
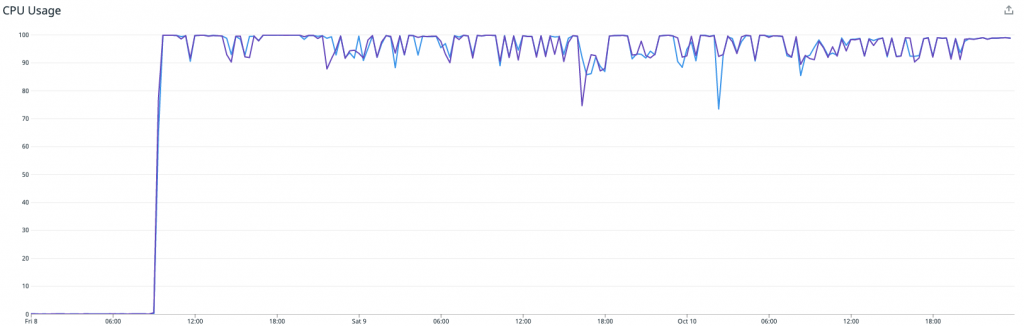
Problem 3a: Übermäßige CPU-Auslastung durch die Writer
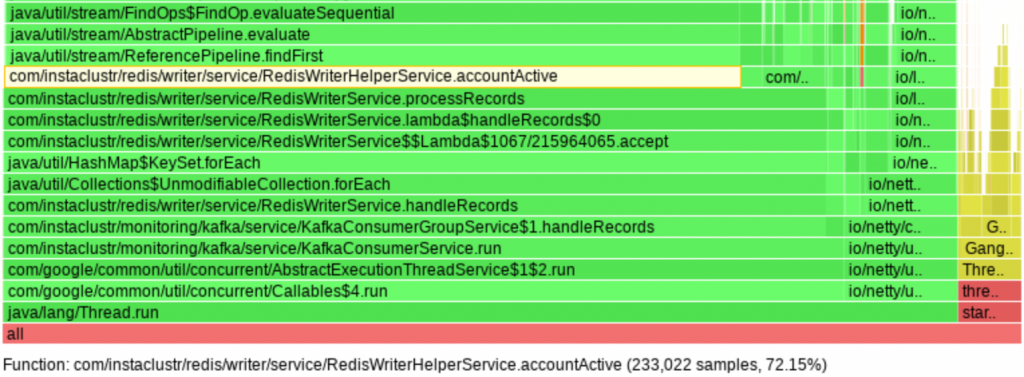
Als Nächstes mussten wir herausfinden, warum der Redis Writer unsere Leistungserwartungen nicht erfüllen konnte. Zu diesem Zweck begannen wir mit der Profilierung durch den async-profiler, der aufdeckte, dass 72 % der CPU-Zeit mit der Durchführung linearer Suchen in Listen kürzlich aktiver Objekt-IDs verbracht wurde. Im Wesentlichen war dies der Code-Pfad, der angibt, ob Kundenmetriken in Redis gespeichert werden sollten. Und tatsächlich gingen 75 % der CPU-Auslastung in das Ermitteln, ob wir bestimmte Metriken speichern sollten, und nur 25 % wurden dafür genutzt, die Metriken tatsächlich in Redis zu speichern. Verschlimmert wurde dies noch durch die Verwendung der Java Stream API auf eine Weise, die zu einer großen Zahl an invokeinterface JVM-Anweisungen führte mit 24 % einen großen Anteil an den 72 % hatte. Bei Listen mit Tausenden von IDs besteht die Lösung in der Verwendung von Hash-Tabellen.3b: Speic
Problem 3b: Speicher des Redis Caching-Clusters voll
Während wir an Problem 3a arbeiteten, ereilte uns eine potenzielle Katastrophe. Unser Monitoring-System meldete dem Support-Team einen Ausfall des internen Redis-Caching-Clusters. Wie sich schnell herausstellte, war dies auf einen vollen Speicher des Clusters zurückzuführen. Wie konnte unser Speicher voll sein, wo wir doch weniger Daten als zuvor verarbeiteten? Und wie konnte unser Speicher voll sein, wo doch unsere Redis-Cluster mit unserer Meinung nach sinnvollen Speicherbegrenzungen belegt waren – in Verbindung mit einer LRU-Verdrängungsstrategie (Least-Recently-Used)?
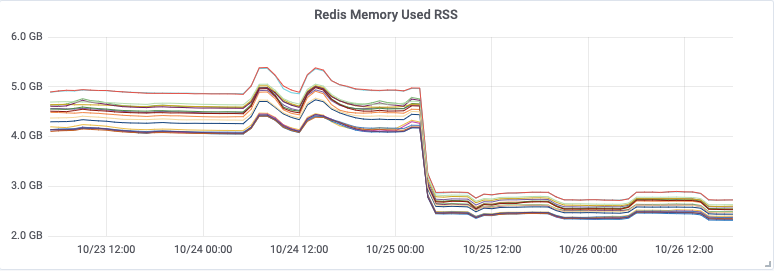
Eine Analyse des neuen Redis Writer-Codes förderte einen Fehler in der TTL-basierten Ablauflogik zutage, der diese bei fast jeder halbwegs bedeutenden Datenmenge beinahe nutzlos machte. Die TTLs wurden nur alle 30 Minuten während einminütiger Intervalle angewendet, sodass die meisten Daten keine TTLs erhielten und es so zu einem unkontrollierten Anstieg der Speichernutzung kam. Dies war eine unnötige Optimierung, die wir beheben konnten, indem wir die TTLs bei jedem Schreiben von Metriken aktualisieren, was eine relativ einfache Änderung darstellte. Doch dies führte uns zu einer anderen wichtigen Frage – warum hatte der Speicherbegrenzungsmechanismus nicht funktioniert?
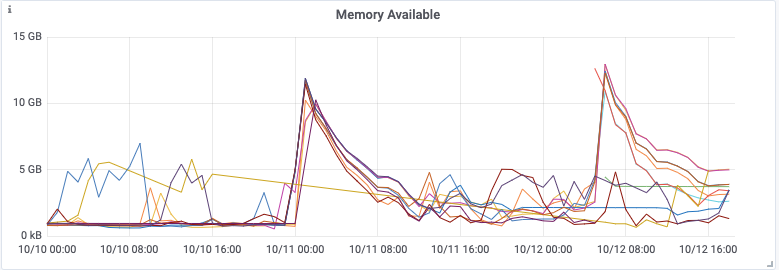
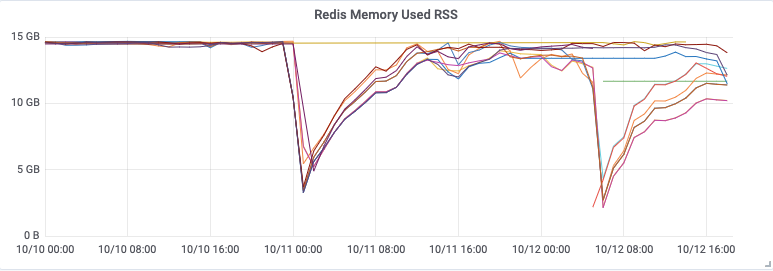
Die von Redis gelieferten Metriken zur Speichernutzung zeigen uns, dass die Speicherbegrenzung eingehalten wurde, zumindest so lange, bis der Cluster zu kippen begann. Was aber überraschte, waren die vom System gemeldeten umgekehrten Spitzen beim verfügbaren Speicher, die teilweise bis auf null reichten!
Wir verglichen die Zeitstempel der Spitzen mit den Redis-Protokollen und stellten fest, dass sie von einer Append-Only-Datei (AOF) verursacht wurden. Weitere Nachforschung förderte das allgemeine Problem zutage, dass die Spitzenspeichernutzung von Redis weit über dem maximalen Speicherlimit liegen konnte (redis#6646). Redis spaltet den Hauptprozess auf, um konsistente Snapshots der Datenbank zu erstellen, die für das AOF-Rewrite benötigt werden. Die Aufspaltung ist typischerweise platzsparend, da sie auf dem COW-Prinzip (Copy-On-Write) basiert. Wenn die Workload jedoch schreibintensiv ist, muss ein erheblicher Anteil der ursprünglichen Speicherseiten kopiert werden. Für diese Workload müssten wir den maximalen Speicher von Redis auf weniger als die Hälfte des Gesamtsystemspeichers begrenzen, und selbst dann müssten wir erst Tests durchführen, um sicherzustellen, dass so das Speicherproblem von Redis behoben wird.
Problem 3c: Ineffizientes Format für Metriken in Redis
Unsere Anwendung speicherte Metriken in Redis als JSON-Objekte in sortieren Sätzen. Nach einigen Durchläufen der Lösung landeten wir bei einem Vorgängermodell, das den Schlüsselnamen in jedem Wert dupliziert. Für den typischen Metrikwert nahm der begonnene Schlüsselname rund die Hälfte des Speichers ein.
Als Beispiel hier ein Schlüssel für die CPU-Last-Metrik eines Knotens:
{46e4157b-e6de-42e1-9c37-5fe5e8d1e676}/metrics/cpuUtilization
Und hier ein Wert, der in diesem Schlüssel gespeichert sein könnte:
{"service":"{46e4157b-e6de-42e1-9c37-5fe5e8d1e676}/metrics/cpuUtilization","time":1623814124123,"value":0,0}
Wenn wir alle redundanten Informationen entfernen, bleibt Folgendes übrig:
{"time":1623814124123}
Zusätzlich zum Service-Namen können wir auch den Wert entfernen, wenn dieser der Standard ist. Durch diese beiden Optimierungen können wir die Speichernutzung ungefähr halbieren.
Versuch 4: Fehlerbehebung, Optimierung und Feinabstimmung
Nachdem die Probleme gelöst waren, fiel die CPU-Nutzung ab, und der Durchsatz stieg an, aber der ständig zunehmende Consumer-Lag wurde kaum weniger. Wir verarbeiteten noch immer nicht genügend Nachrichten, um mit der Zahl an einlaufenden Ereignissen Schritt zu halten.
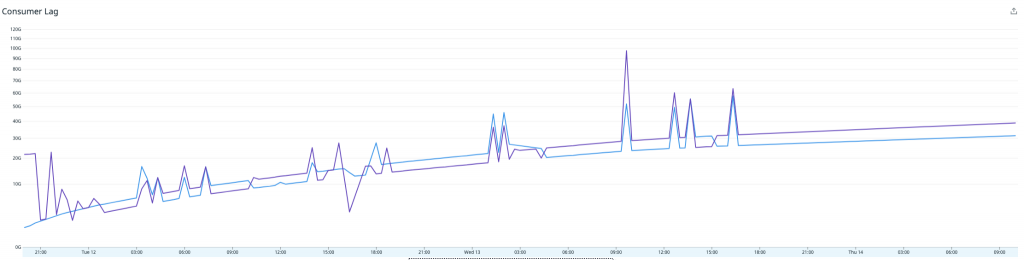
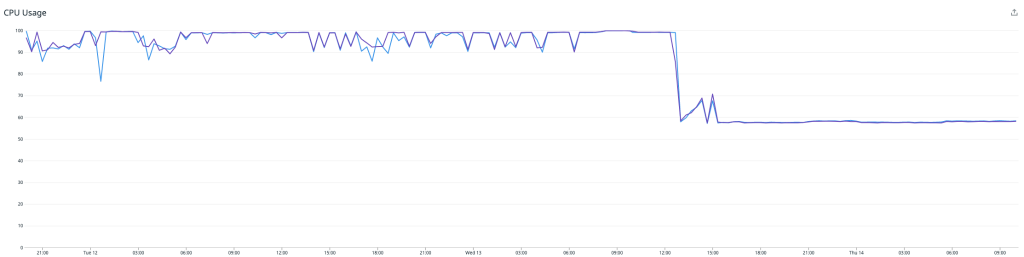
Die niedrige CPU-Auslastung zusammen mit dem Fehlen anderer offensichtlicher Ressourcenengpässe deutete darauf hin, dass eine Art von Thread-Konflikt vorlag. Der Redis Writer verwendet mehrere Kafka-Consumer-Threads, aber alle Threads nutzen – wie von der Lettuce-Dokumentation empfohlen – dieselbe Instanz des Lettuce Redis-Clients. Wir ignorierten die Empfehlung und probierten eine Refaktorierung des Redis Writers, sodass jeder Consumer-Thread seinen eigenen Lettuce Client erhält.
Erfolg! Unmittelbar nach der Inbetriebnahme des neuen Redis Writers verdoppelte sich der Durchsatz, und der Consumer-Lag ging zum ersten Mal zurück.
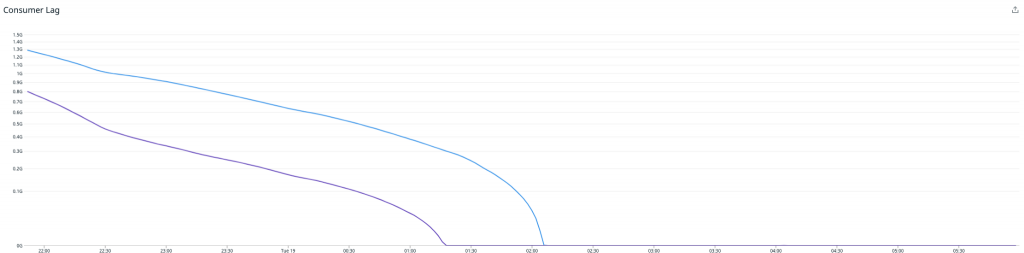
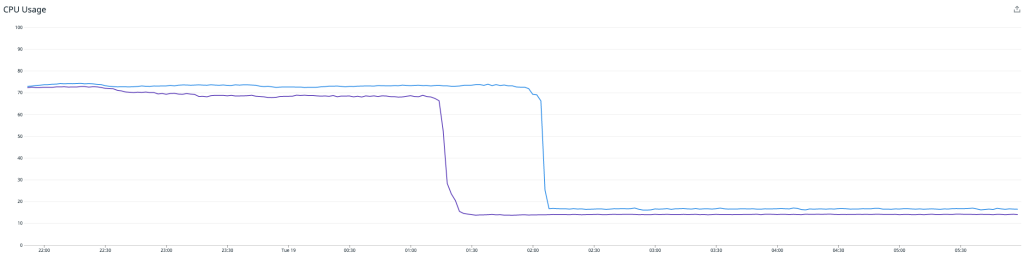
Hier ist anzumerken, dass eine höhere Last bestehen bleibt, während der Writer den Rückstand aufholt. Sobald dies abgearbeitet ist, fällt die CPU-Last deutlich auf rund 15 %. An diesem Punkt müssen wir nur noch die Redis Writer-Instanzen verkleinern, um die CPU-Nutzung zwischen dem Redis Writer und dem Redis-Cluster bestmöglich abzustimmen, wobei wir reichlich Raum für zukünftiges Wachstum lassen.
Aktivierung des Lesens von der API
Jetzt haben wir also eine Pipeline, die kontinuierlich die letzten 15 Minuten an Metriken für alle Kundenknoten erfasst, die die API kürzlich genutzt haben. Doch das alles nützt nichts, solange wir nicht unsere API auf die Abfrage von Redis erweitern!
Das letzte Stück Arbeit bestand darin, unseren API-Instanzen zu erlauben, Metriken bei Redis abzufragen.
Am Ende filtert unsere API-Logik nur zeitbasiert nach Metrikabfragen und danach, ob sie in den letzten 15 Minuten liegen – und sie fragt Redis zuerst ab. Redis ist schnell, wenn es ums Lesen geht, aber extrem schnell, wenn es darum geht zu sagen, dass kein zwischengespeicherter Wert vorhanden ist. Statt also programmatisch herauszufinden, ob eine bestimmte Metrik zwischengespeichert ist, versuchen wir es zuerst bei Redis, und wenn sie dort nicht ist, fragen wir sie bei Cassandra ab. Dieser „Fail-Fast“-Ansatz an das Abrufen von Metriken führt im schlimmsten Fall zu minimal höherer Latenz.
Der erste Einsatz der API-Funktion funktionierte ziemlich gut, und wir bemerkten eine Reduzierung der Lesevorgänge von unserem Cassandra-Cluster. Allerdings gab es weiterhin einige Randfälle, die mit einer geringen Anzahl von Metriken Probleme bereiteten und uns dazu zwangen, die Funktion abzuschalten und eine Lösung zu entwickeln. Diese abschließende Lösung wurde am 27. Oktober eingeführt.
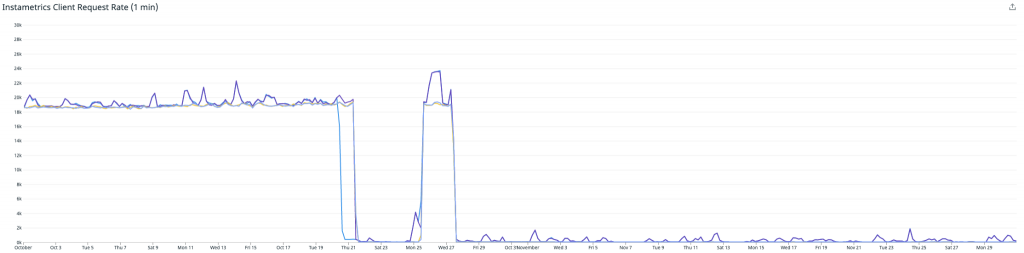
Die erste Grafik zeigt die Verringerung der Anzahl von Anfragen, die bei unserem Instametrics Cassandra-Cluster von unserer API eingingen – woraus deutlich wird, dass wir diese Lesevorgänge fast vollständig beseitigt haben.
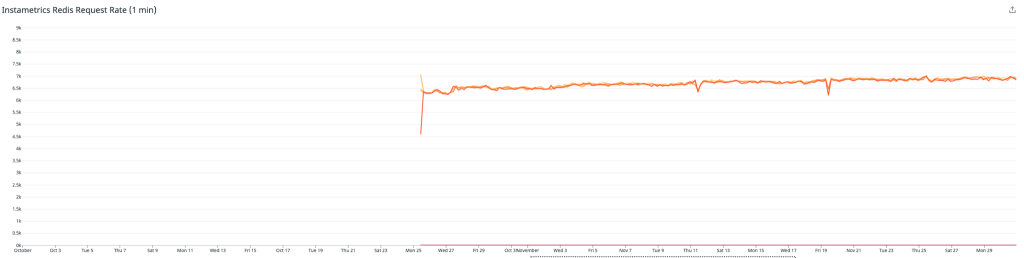
Diese Grafik zeigt die Zahl der Lesevorgänge, die auf unseren Redis-Cluster übertragen wurden (bitte beachten, dass diese Metrik erst am 25. Oktober eingeführt wurde).
Der interessante Teil ist, dass dies tatsächlich keine großen Auswirkungen auf unsere API-Latenzen hatte. Wir melden noch immer sehr ähnliche Latenzen von P95 (blau) und P50 (lila).
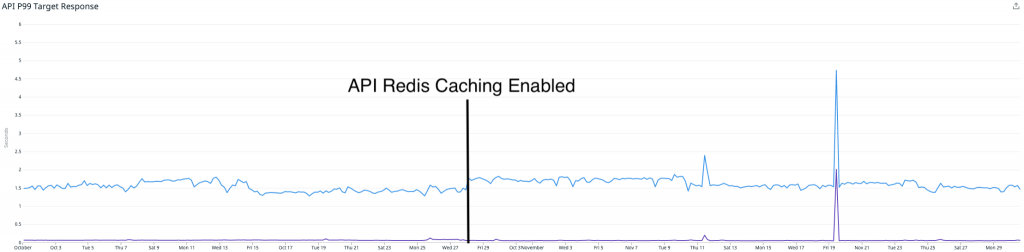
Dies lässt sich durch zwei Dinge erklären:
- Unser Cassandra-Cluster war zu dieser Zeit mit über 90 Knoten und i3.2xlarge sehr groß, was eine extrem schnelle lokale Speicherung umfasste. Dadurch wurden alle Leseanforderungen tatsächlich noch immer in einem vernünftigen Zeitrahmen bedient.
- Der Redis-Cluster ist deutlich kleiner als unser Cassandra-Cluster, und wir können noch immer einige Leistungsverbesserungen vornehmen. Eine besteht darin, von AOF-Persistence auf Diskless-Persistence zu wechseln, was die Leistung für eine große, schreibintensive Workload wie unsere verbessern würde.
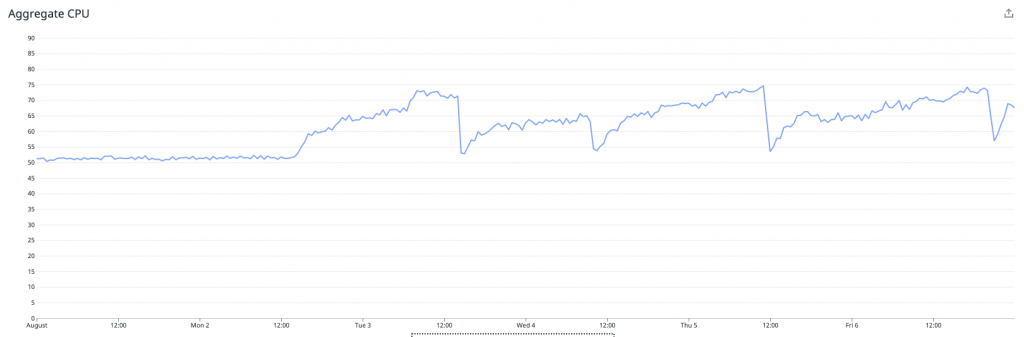
An diesem Punkt besteht der Hauptvorteil unseres Cachings von Metriken mit Redis darin, wie es sich auf den Zustand unseres Cassandra-Clusters ausgewirkt hat. Als wir mit dem Redis-Caching begannen, hatten wir einen i3.2xlarge Cassandra-Cluster mit 90 Knoten. Dieser wurde Anfang September in einen i3.4xlarge Cluster mit 48 Knoten umgewandelt, um eine höhere Verarbeitungskapazität zu erreichen.
Die erste Verbesserung des Clusters waren die Kafka-basierten Roll-ups, die am 28. September eingeführt wurden, und dann das Redis-Caching etwa einen Monat später, am 27. Oktober.
Aus den nachfolgenden Grafiken geht die erhebliche Verbesserung hervor, die beide Releases auf die CPU-Auslastung, die Betriebssystemlast und die Zahl der Lesevorgänge auf dem Cassandra-Cluster hatten.
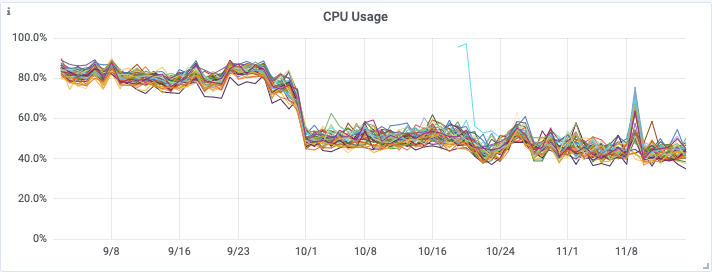
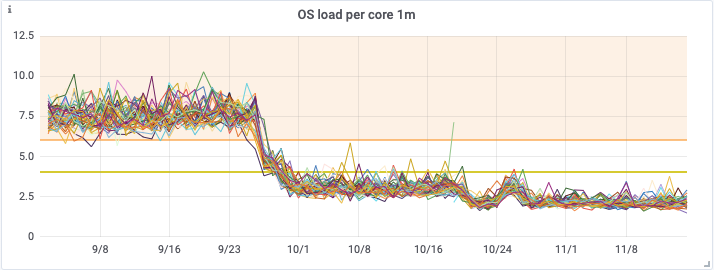
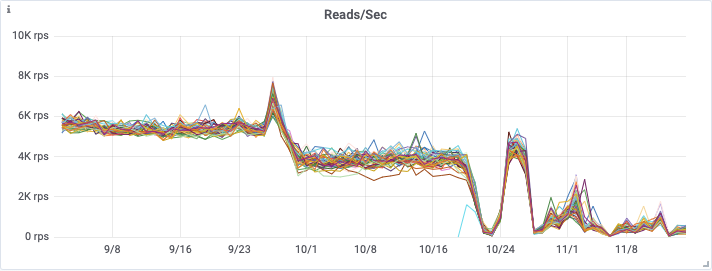
Dies ermöglichte uns schließlich Mitte November eine Verkleinerung unseres Cassandra-Clusters von einem i3.4xlarge Cluster mit 48 Knoten zu einem i3en.2xlarge Cluster mit 48 Knoten. Dies bedeutet erhebliche Einsparungen bei den Infrastrukturkosten, während der neuerdings gute Zustand unseres Clusters einschließlich der Leselatenzen erhalten bleibt.
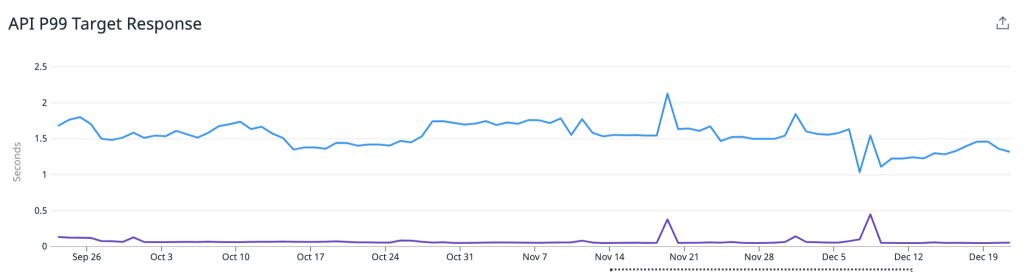
In den letzten Monaten ist mit unseren Redis Writern alles gut gelaufen, wir mussten keinerlei größere Arbeiten durchführen, um eine stabile Caching-Pipeline aufrechtzuerhalten, und die Auswirkungen bei den Kunden sind weiterhin sehr vielversprechend.
Im nächsten Blog erklären wir, wie ein Redis-Cache uns ermöglichte, unseren neuen Prometheus Autodiscovery Endpoint aufzubauen, der es Kunden erleichtert, mit Prometheus alle verfügbaren Metriken zu erfassen.
RabbitMQ® ist eine eingetragene Marke von VMware, Inc. in den U.S.A. und anderen Ländern.
Der Originalartikel wurde am 2.März von Kuangda He auf Instaclustr.com auf Englisch veröffentlicht.
| Kategorien: | HowTos Instaclustr® News |
|---|---|
| Tags: | Cassandra Kafka Redis |

über den Autor
Carsten Meskes
Marketing and Operations Specialist
zur Person
Carsten Meskes, Mitarbeiter seit 2016, kümmert sich hauptsächlich um credativ und Instaclustr Marketing im DACH-Bereich und in Europa. Weiterhin unterstützt er er auf internationaler Ebene verschiedene Transformationsprozesse innerhalb der gesamten Instaclustr-Gruppe. Mit vielfälltiger Sprachbegabung, langjährigen Aufenthalts in Japan und Ausbildung als Coach ist er unser Ansprechpartner für Kulturelles und Kommunikation.