Apache Kafka® Microservices mit Cadence-Workflows optimieren
| Kategorien: | HowTos |
|---|---|
| Tags: | apachekafka® cadence |
In „Workflows mit Cadence optimieren“ haben wir Cadence, eine neue skalierbare, auf Entwickler fokussierte Open-Source-Workflow-Engine, vorgestellt. Cadence ist eine großartige Lösung für ein äußerst fehlertolerantes, zustandsabhängiges Workflow-Management, auch bekannt als „Orchestrierung“ (in Anlehnung an die Idee, dass ein Dirigent ein Orchester leitet). Eine andere beliebte Architektur für große nachrichtenbasierte dezentrale Systeme verwendet jedoch einen losgelösten Ansatz, der als „Choreografie“ bekannt ist (in Anlehnung an die Idee, dass Tänzer mit ihren unmittelbaren Nachbarn interagieren). Apache Kafka ist ein gängiges Beispiel und erlaubt zahlreichen Microservices, skalierbar und mit geringer Latenz miteinander zu kommunizieren, ohne dass eine zentrale Zustandsverwaltung erforderlich ist.
In vielen Unternehmen ist es allerdings üblich, schon jetzt zahlreiche Kafka-Microservices zu nutzen. Darüber hinaus verwenden typische moderne Unternehmenssysteme mehrere Technologien, sodass man im Endeffekt beide Architekturen kombinieren und Kafka-Microservices mit Cadence-Workflows integrieren muss. Anstatt nur ein Orchester oder nur Tänzer zu engagieren, müssen Sie ein Ballett aufführen, das beides kombiniert.
(Quelle: Shutterstock)
Es gibt eine ganze Reihe von Anwendungsfälle für Kafka in Kombination mit Cadence, in diesem Blog konzentrieren wir uns jedoch auf die Vorteile bei der Wiederverwendung von Kafka-Consumer-basierten Microservices aus Cadence-Workflows. Wie kann man also eine Nachricht von Cadence an Kafka senden, um eine Activity in Kafka zu starten, und wie wartet man asynchron auf eine Antwort und empfängt diese schließlich? In meiner Blog-Serie Anomalia Machina habe ich beispielsweise darüber berichtet, wie ich ein System zur Erkennung von Anomalien als Kafka-Consumer implementiert habe.
Was aber, wenn wir eine Prüfung auf Abweichungen im Rahmen eines Cadence-Workflows durchführen wollen?
Um eine Nachricht an Kafka zu senden, muss lediglich ein Kafka-Producer mit den richtigen Metadaten im Rahmen einer Cadence Activity Method verwendet werden, um sicherzustellen, dass eine Antwort gesendet/empfangen werden kann. Es gibt dabei verschiedene Wege, auf eine Antwort zu warten und sie zu erhalten. Das schauen wir uns jetzt mal genauer an.
1. Eine Nachricht von Cadence an Kafka senden

(Quelle: Shutterstock)
Glücklicherweise ist es ein wenig einfacher, eine Nachricht an Kafka zu senden, als Flaschenpost zu versenden, in der Hoffnung, dass die enthaltene Nachricht auch empfangen wird.
Bereiten Sie also zunächst Ihre „Flasche“ (den Kafka-Producer) vor, ich habe beispielsweise diese Eigenschaftsdatei verwendet:
Properties kafkaProps = new Properties();
try (FileReader fileReader = new FileReader("producer.properties")) {
kafkaProps.load(fileReader);
} catch (IOException e) {
e.printStackTrace();
}
Die Datei producer.properties für einen Instaclustr Managed Kafka-Dienst wird folgendermaßen konfiguriert (die clusterspezifischen Details müssen über die Instaclustr-Konsole oder die Verwaltungs-API eingegeben werden):
bootstrap.servers=IP1:9092,IP2:9092,IP3:9092
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-256
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \
username="kafakUser" \
password="kafkaPassword";
Anschließend wird eine Cadence Activity Method festgelegt, die eine Nachricht an Kafka sendet:
public interface ExampleActivities {
@ActivityMethod(scheduleToCloseTimeoutSeconds = 60)
String sendMessageToKafka(String msg);
}
public static class ExampleActivitiesImpl implements ExampleActivities {
public String sendMessageToKafka(String msg) {
// The id is the workflow id
String id = Activity.getWorkflowExecution().getWorkflowId();
// Record contains: topic, key (null), value
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("topic1", "", msg);
// Add the workflow id to the Record Header
producerRecord.headers().add(new RecordHeader("Cadence_WFID", id.getBytes()));
try (KafkaProducer<String, String> producer = new KafkaProducer<>(kafkaProps)) {
producer.send(producerRecord);
producer.flush();
} catch (Exception e) {
e.printStackTrace();
}
return "done";
}
}
Im Kafka-Datensatz wird das Zielthema, ein Nullschlüssel und der Nachrichtenwert angegeben. Mit dem Kafka-Header wird die Workflow-ID an Kafka übergeben, damit das System weiß, woher die Nachricht stammt. Ein Header enthält ein Key-Value-Paar, und jeder Kafka-Datensatz kann mehrere Header haben. Die Verwendung von Kafka-Headern zur Unterstützung von OpenTracing ist bereits bekannt.
Warum werden Header für die Workflow-ID verwendet und nicht etwa der Datensatzschlüssel?
Nun, wenn die vorhandenen Kafka-Microservices wiederverwendet werden sollen, dürfen sich die Änderungen auf der Kafka-Seite nur minimal auswirken. Bestehende Kafka-Consumers gehen von dem Schlüssel und dem Wert des Datensatzes aus, aber die Idee hinter einem Kafka-Header ist, dass man optionale Metadaten hinzufügt, wodurch bestehende Implementierungen nicht unterbrochen, sondern leicht erweitert werden können, sodass die Metadaten verstanden werden und eine entsprechende Reaktion erfolgt.
Wenn es Ihnen nur darum geht, eine Nachricht an Kafka zu senden und dann mit dem übrigen Workflow fortzufahren („Fire-and-Forget“), dann ist Ihre Arbeit hiermit getan. Eigentlich brauchen Sie keine Workflow-ID zu senden, wenn Sie keine Antwort erwarten (es sei denn, es gibt einen anderen Grund, warum der Kafka-Consumer wissen muss, dass die Nachricht von Cadence stammt). Der Workflow (in BPMN-ähnlicher Darstellung) sähe dann so aus (mit einer optionalen zweiten Aufgabe usw.).
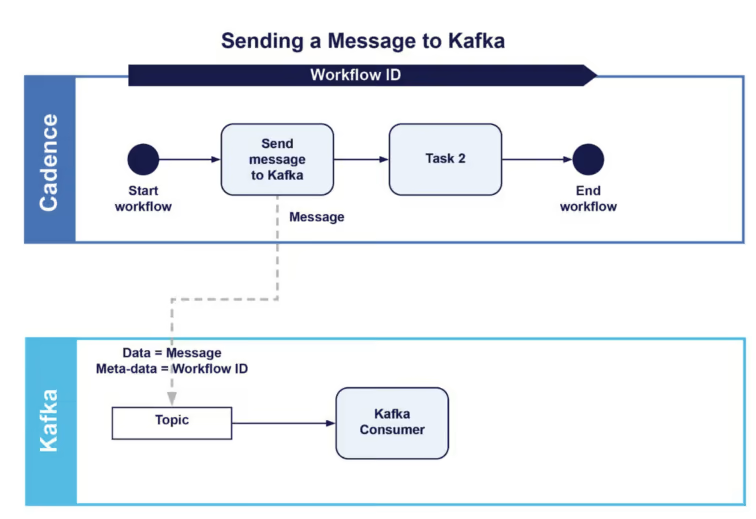
Wir gehen allerdings davon aus, dass es in unserem Anwendungsfall eine Verarbeitung auf der Kafka-Seite als Reaktion auf den Empfang der Nachricht gibt. Das Ergebnis muss wieder vom Workflow empfangen werden, bevor weitere Activities durchgeführt werden können. Wie lässt sich die Schleife beenden?
2. Einführung von Cadence-Signalen
Signallampen werden zur Kommunikation zwischen Schiffen auf See verwendet. https://commons.wikimedia.org/wiki/File:Seaman_send_Morse_code_signals.jpg
Für eine Antwort von Kafka brauchen wir etwas Besseres als Flaschenpost. Cadence-Signale basieren auf UNIX-ähnlichen IPC-Signalen (Interprozesskommunikation), die es einem Prozess oder einem bestimmten Thread erlauben, Nachrichten zu senden, und ihn über ein Ereignis zu informieren (z.B. „kill -9 <pid>“!). In einem kürzlich erschienenen Blog über Apache ZooKeeperTM und Curator haben wir auch über die Verwendung von Signalen (Semaphoren, Abschnitt 3.3) berichtet.
Aus der Dokumentation geht hervor, dass Cadence-Signale:
„… einen vollständig asynchronen und dauerhaften Mechanismus zur Bereitstellung von Daten für einen laufenden Workflow bieten. Wenn ein Signal für einen laufenden Workflow empfangen wird, hält Cadence das Ereignis und die Nutzdaten in der Workflow-Historie fest. Im Workflow kann das Signal später jederzeit verarbeitet werden, ohne dass die Informationen verloren gehen. Außerdem kann die Ausführung des Workflows durch Blockieren eines Signalkanals gestoppt werden.”
In meinem ersten Cadence-Blog habe ich darüber berichtet, dass es bei jedem Workflow eine Schnittstelle und eine Implementierung mit mehreren möglichen Methoden gibt, aber nur eine Methode mit der Kennzeichnung @WorkflowMethod, die anzeigt, bei welcher Methode es sich um den Einstiegspunkt für den Workflow handelt. Es gibt auch andere Methoden, die mit @SignalMethod gekennzeichnet sind. Zum Beispiel:
public interface ExampleWorkflow {
@WorkflowMethod(executionStartToCloseTimeoutSeconds = 120, taskList = activityName)
String startWorkflow(String name);
@SignalMethod
void signalKafkaReply(String name);
}
Und die Umsetzung dieser beiden Methoden:
public static class ExampleWorkflowImpl implements ExampleWorkflow { String message = "";
private ExampleActivities activities = null;
public ExampleWorkflowImpl() {
this.activities = Workflow.newActivityStub(ExampleActivities.class);
}
@Override
public String startWorkflow(String msg) {
String r1 = activities.sendMessageToKafka(msg);
Workflow.await(() -> message != "");
System.out.println("workflow got signal = " + message);
return message;
}
}
@Override
public void signalKafkaReply(String msg) {
message = msg;
}
}
Es können ganz unterschiedliche Signalmethoden verwendet werden, aber für dieses Beispiel verwende ich aus praktischen Gründen nur eine Signalmethode. Jedes Mal, wenn ein ExampleWorkflow.signalKafkaReply-Signal an eine Workflow-Instanz gesendet wird, kommt es zum Aufruf der entsprechenden Signalmethode. Signalmethoden geben nie einen Wert zurück, sondern bewirken etwas im Hintergrund: In diesem Fall wird die Nachrichtenvariable mit dem Wert des Signalarguments belegt.
Abschließend ist noch anzumerken, dass die startWorkflow-Methode implementiert wurde, die nun die sendMessageToKafka-Activity Methode abruft. Danach wird sie sofort durch die Funktion Workflow.await() blockiert, und zwar so lange, bis die Funktion, die sie als Parameter erhält, auf True gesetzt wird, d. h. bis dieser Workflow ein Signal mit einem Nachrichtenwert erhält, der ungleich null ist. Das Design von Cadence lässt eine Auswertung der Bedingung nur bei Statusänderungen des Workflows zu (d. h. es findet kein Abruf statt).
Wie lassen sich also Cadence-Signale für die Integration mit Kafka nutzen?
2. Cadence-Signale mit Kafka integrieren: Erster Ansatz
Im Folgenden wird der Workflow unter Verwendung von Signalen beschrieben:
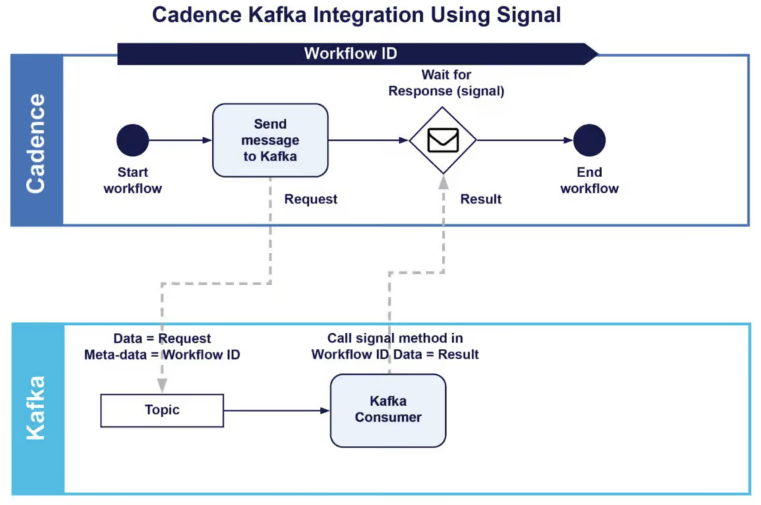
Wir erfahren, wie das gesamte Muster funktioniert, also das Senden einer Nachricht an Kafka, das Warten auf eine Antwort und die Meldung der richtigen Workflow-Instanz von Kafka. Die ersten zwei Teile haben wir bereits behandelt. Der letzte Teil der Aufgabe ist die Frage, wie ein Kafka-Consumer eine bestimmte Workflow-Instanz melden kann. Im zuvor genannten Kafka-Producer haben wir die Workflow-ID im Datensatz-Header gesendet. So kann der Kafka-Consumer diese Information abrufen und
- erkennen, dass der Datensatz von Cadence stammt, und
- die Antwort an den richtigen Workflow zurückschicken.
Der Kafka-Consumer muss so konfiguriert werden, dass er sich zum einen mit dem Kafka-Cluster verbindet, an den der Datensatz gesendet wurde, und zum anderen mit dem Cadence-Cluster, der diesen Workflow verwaltet (was zu KafkaConsumer– und WorkflowClient-Objekten führt). Die Hauptabrufschleife des Kafka-Consumer sieht so aus:
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(kafkaProps)) {
consumer.subscribe(Collections.singleton("topic1"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
String id = "";
// If the header has Cadence_WFID key then we send the response to Cadence
for (Header header : record.headers()) {
if (header.key().matches("Cadence_WFID"))
id = new String(header.value());
}
if (id != "")
{
ExampleWorkflow workflowById = workflowClient.newWorkflowStub(ExampleWorkflow.class, id);
workflowById.signalKafkaReply("Kafka consumer received value = " + record.value());
}
// else don't send signal! But do whatever is normal
}
}
Es handelt sich hierbei nur um ein Anschauungsbeispiel, d. h. der Kafka-Consumer verarbeitet die Anfrage nicht wirklich, und die Antwort ist nur eine Zeichenkette, die den Anfragewert enthält. Wird im Header „Cadence_WFID“ gefunden, wird zunächst mit WorkflowClient.newWorkflowStub() ein neuer Stub für den Workflow mit ExampleWorkflow.class und der Workflow-ID erstellt. Anschließend wird das Signal durch Aufruf der Signalmethode an diesen Stub gesendet. Andernfalls erfolgt die normale Verarbeitung und Lieferung der Ergebnisse. Wenn der Workflow das Signal erhalten hat, wird die Blockierung aufgehoben, und er setzt seine Arbeit fort, indem er die Antwort verwendet oder gegebenenfalls weitere Activities durchführt.
In diesem Beispiel wird davon ausgegangen, dass für jede an Kafka gesendete Nachricht nur ein Signal als Antwort gesendet wird. In Kafka können auch Consumer-Gruppen angelegt werden, sodass theoretisch mehrere Signale gesendet werden könnten. In diesem Fall spielt das jetzt keine Rolle, da es nur auf das erste Signal ankommt. Bei anderen Beispielen müssen eventuell mehrere Signale richtig verarbeitet werden.
Mehr Infos zu Cadence-Signalen gibt es hier und hier.
3. Abschluss von Activities in Cadence: Zweiter Ansatz

Abschlussarbeiten auf der Sydney Harbour Bridge („den Bogen spannen“). https://commons.wikimedia.org/wiki/File:SLNSW_44281_Sydney_ferry_Kubu_passes_near_the_Harbour_Bridge_as_the_lower_chord_is_ready_for_joining.jpg circa 1930
Der Abschluss von asynchronen Activities in Cadence (Cadence Asynchronous Activity Completion) ist ein alternativer Ansatz zur Lösung dieses Problems. Mehr Infos zum Abschluss von Activities in Cadence gibt es hier, hier und hier. Die Dokumentation zeigt, dass es sich um eine perfekte Ergänzung handelt:
Manchmal geht der Lebenszyklus einer Activity über einen synchronen Prozessaufruf hinaus. So kann zum Beispiel eine Anfrage in eine Warteschlange gestellt werden und zu einem späteren Zeitpunkt kommt eine Antwort und wird von einem anderen Worker-Prozess abgeholt. Die gesamte Anfrage-Antwort-Interaktion lässt sich als eine einzige Cadence-Activity modellieren.
Wie unterscheidet sich dieser Ansatz von dem Signalansatz? Der Hauptunterschied liegt in der Blockierung, die nun (konzeptionell) in der Activity-Method und nicht mehr im Workflow selbst stattfindet. Außerdem ist der Aufruf zum Abschluss mit der Activity und nicht mit dem Workflow verbunden. Es handelt sich jedoch immer noch um eine „Punkt-zu-Punkt“-Kommunikation, die über Prozessgrenzen hinweg funktioniert Dieser Workflow sieht dann folgendermaßen aus:
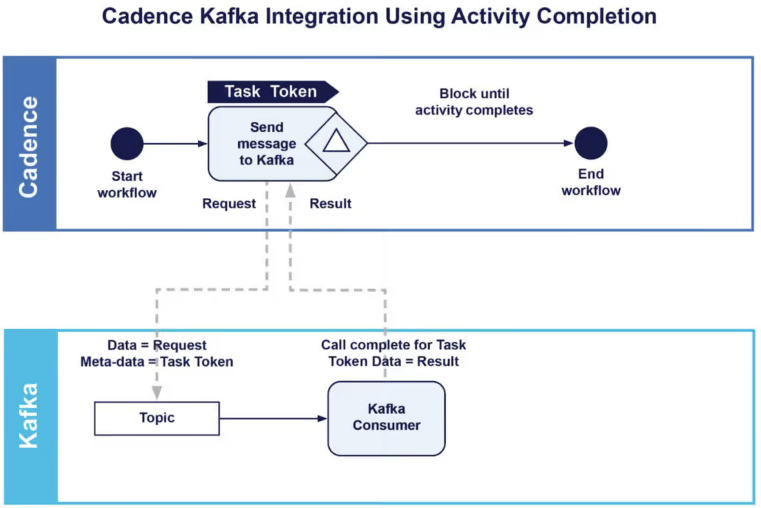
Die Implementierung des Haupt-Workflows ist jetzt ganz einfach, da weder Wartezeiten noch eine Signalmethode erforderlich sind:
public static class ExampleWorkflowImpl implements ExampleWorkflow {
private ExampleActivities activities = null;
public ExampleWorkflowImpl() {
this.activities = Workflow.newActivityStub(ExampleActivities.class);
}
@Override
public String startWorkflow2(String msg) {
String r1 = activities.sendMessageToKafka2(msg);
return r1;
}
}
Die Activity-Method ist jedoch etwas komplizierter und sieht wie folgt aus:
public String sendMessageToKafka2(String msg) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("topic1", "", name);
// The task token is now used to correlate reply.
byte[] taskToken = Activity.getTaskToken();
producerRecord.headers().add(new RecordHeader("Cadence_TASKID", taskToken));
try (KafkaProducer<String, String> producer = new KafkaProducer<>(kafkaProps)) {
producer.send(producerRecord);
producer.flush();
} catch (Exception e) {
e.printStackTrace();
}
// Don’t complete - wait for completion call
Activity.doNotCompleteOnReturn();
// the return value is replaced by the completion value
return "ignored";
}
Alternativ zur Workflow-ID (wie zuvor bei den Signalen beschrieben) wird nun der Task-Token ermittelt und als Wert des Schlüssels „Cadence_TASKID“ in den Kafka-Header eingefügt. Die Nachricht wird wie zuvor mit einem Kafka-Producer an das Kafka-Topic gesendet. Die Activity zeigt dann jedoch mit der Methode Activity.doNotCompleteOnReturn() an, dass sie bei Rückgabe nicht „abgeschlossen“ ist. Der Rückgabewert wird „ignoriert“ (es kann sich dabei um einen beliebigen Wert handeln). Doch was bedeutet das? Grundsätzlich wird jeder Wert, der von der Activity-Method zurückgegeben wird, verworfen und später durch den Wert ersetzt, der durch den Aufruf zum Abschluss bereitgestellt wird.
Auch beim Kafka-Consumer gibt es einige Änderungen, und zwar:
ActivityCompletionClient completionClient = workflowClient.newActivityCompletionClient();
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(kafkaProps)) {
consumer.subscribe(Collections.singleton("topic1"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
byte[] task = null;
// If the header has key = Cadence_TASKID then send response to Cadence task using completion
for (Header header : record.headers()) {
if (header.key().matches("Cadence_TASKID"))
task = Arrays.copyOf(header.value(), header.value().length);
}
if (task != null)
completionClient.complete(task, "Kafka consumer received value = " + record.value());
// else process as normal
}
}
Zunächst wird ein ActivityCompletionClient unter Verwendung der WorkflowClient-Instanz erstellt (die mit den richtigen Cadence-Cluster-Einstellungen angelegt wurde). Wird in Kafka der Schlüssel „Cadence_TASKID“ im Datensatz-Header für ein Ereignis gefunden, wird die Abschlussmethode mit dem Task-ID-Wert und einem Response-Wert aufgerufen. Dieser Response-Wert wird von der Activity-Method zurückgegeben, die blockiert ist und auf den Abschluss wartet.
Im Kafka-Consumer kann ein „Handler“ für den Signalansatz und den Abschlussansatz vorhanden sein. Wenn keiner der beiden Ansätze im Header vorhanden ist, findet eine normale Verarbeitung statt.
Das Thema „Abschluss“ war mir immer noch ein Rätsel, also fragte ich unsere Entwickler nach weiteren Details (danke Kuangda, Matthew und Tanvir). Hier das Wichtigste in Kürze:
Der Abschluss (Completion) ist ein praktisches paralleles Programmiermuster, um auf einen externen Callback zu warten, der das Ergebnis liefert (Push), anstatt das Ergebnis abzufragen (Pull). Der ursprüngliche Rückgabewert wird ignoriert, da er eigentlich nur einen speziellen Fehler zurückgibt (mithilfe eines Golang-Fehlerbehandlungsmusters), der signalisiert, dass das Resultat, das vom Completion-Callback geliefert wird, noch aussteht.
In der Cadence-go-Client-Dokumentation wird dies näher ausgeführt. Bei Java gibt es einen ähnlichen Mechanismus, der Futures und CompletableFutures verwendet, und einen weiteren Blog.
4. Kafka und Cadence: Fazit

(Quelle: Shutterstock)
Wir sind jetzt am Ende dieses Blogs angelangt und haben die Ansätze „Signale“ und „Abschluss von Activities“ kennengelernt – zwei Lösungen für die Integration von Kafka-Microservices mit Cadence-Workflows, mit denen sich die zwei Welten der Choreografie und der Orchestrierung perfekt kombinieren lassen. Beide Lösungen funktionieren einwandfrei. Ich hoffe, die „Aufführung“ hat Ihnen gefallen.
Der Unterschied besteht im Wesentlichen darin, dass „Signale“ auf der Ebene von Workflows arbeiten, und „Abschlüsse von Activities“ dafür detaillierter angelegt sind und auf der Ebene von Aufgaben/Activities agieren. Zur Korrelation komplexerer Workflows mit mehreren gleichzeitigen Aufgaben/Activities, die mit Kafka kommunizieren, kann dies durchaus ein Vorteil sein.
Beim Ansatz „Abschluss“ regelt das Activity Timeout die Zeitüberschreitung für den gesamten Nachrichtenumlauf zu und von Kafka. Beim Ansatz „Signal“ hingegen bieten die separate Zeitüberschreitung für die Activity (Senden der Nachricht an Kafka) und das anschließende Warten auf die Antwort von Kafka mehr Flexibilität.
Abschließend sei noch darauf hingewiesen, dass „Signale“ und „Abschluss von Aktivtäten“ einen Remote-Aufruf darstellen und eine Verzögerung beim Kafka-Consumer verursachen. Der Ansatz „Signale“ erfordert 2 Remote-Aufrufe, während der Ansatz „Abschluss“ nur 1 Remote-Aufruf benötigt und daher eventuell etwas schneller ist. Es kann auch sein, dass die Anzahl der Kafka-Topic-Partitionen und -Consumer erhöht werden muss, um einen ausreichenden Durchsatz zu erzielen.
Wir unterstützen Sie gerne
Ob Cadence, Debian oder PostgreSQL: mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich, können credativ und Instaclustr Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Sie möchten mehr über Cadence lernen und über die Vorteile die es Ihrer Organisation bietet. Dann laden Sie sich unser englischsprachiges Whitepaper runter.
Sollten Sie Fragen zu unserem Artikel haben oder würden sich wünschen, dass unsere Spezialisten sich Ihr System angucken und Ihre Infrastruktur optimieren, dann schauen Sie doch vorbei und melden sich über unser Kontaktformular oder schreiben uns eine E-mail an info@credativ.de.
Über unsere Mutterfirma Instaclustr bieten wir auch eine komplett verwaltete Plattform für Cadence an.
Original englischsprachige Artikel auf Instaclustr.com
- Part 1: Spinning Your Workflows With Cadence!
- Part 2: Spinning Apache Kafka® Microservices With Cadence Workflows
- Part 3: Spinning your drones with Cadence
- Part 4: Architecture, Order and Delivery Workflows
- Part 5: Integration Patterns and New Cadence Features
- Part 6: How Many Drones Can We Fly?
Folgen Sie der Reihe auf credativ.de: Drohnen fliegen lassen mit Cadence
- Teil 1: Workflows mit Cadence optimieren
- Teil 2: Apache Kafka® Microservices mit Cadence-Workflows optimieren
- Teil 3: Drohnen fliegen lassen mit Cadence
- Teil 4: Architektur, Bestellungs- und Lieferungs-Workflows
- Teil 5: Integrationsmuster und neue Cadence-Funktionen
- Teil 6: Wie viele Drohnen können wir fliegen lassen?
| Kategorien: | HowTos |
|---|---|
| Tags: | apachekafka® cadence |

über den Autor
Paul Brebner
zur Person
Paul is the Technology Evangelist at Instaclustr/Spot by NetApp. For the past five years, he has been learning new scalable Big Data technologies, solving realistic problems, building applications, and blogging and talking about Apache Cassandra, Apache Spark, Apache Kafka, Redis, Elasticsearch, PostgreSQL, Cadence, and many more open source technologies. Since learning to program on a VAX 11/780, Paul has extensive R&D, teaching, and consulting experience in distributed systems, technology innovation, software architecture and engineering, software performance and scalability, grid and cloud computing, and data analytics and machine learning. Paul has also worked at Waikato University (NZ), UNSW, CSIRO, UCL (UK), NICTA/ANU, and several tech start-ups. Paul has an MSc in Machine Learning and a BSc (Computer Science and Philosophy).